Our
Projects
Cyber Data Id Comparison
The purpose of this project is to build an end-to-end ETL pipeline by using the csv files that are uploaded automatically each month to a designed folder. For the ETL process , we have used AWS service including Lambda, S3, Glue, and Athena.
📁 Tech Stack:
1. Python + Spotipy – API Integration
2. AWS Lambda – Code execution (ETL)
3. Amazon S3 – Scalable storage
4. AWS CloudWatch – Automation & scheduling
5. AWS Glue – Crawling & cataloging
6. Amazon Athena – SQL-based analysis
US Airline Traffic Data
Developed an interactive Power BI dashboard to analyze over 1 million U.S. airline flight records. The report highlights key metrics such as total flights, cancelled/diverted flights, average delays, and flight duration. Users can filter by airline or day of the week to explore patterns in cancellations and delays. Visuals include bar charts, KPI cards, and gauges to support decision-making for operational improvements. This project demonstrates strong skills in data modeling, DAX, and advanced visual storytelling.
Spotify end-to-end Data Engineering
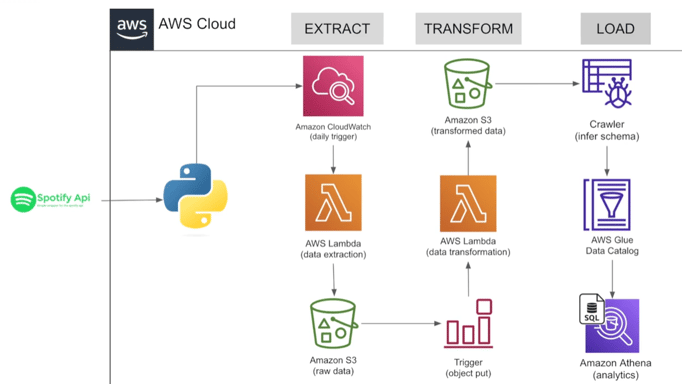
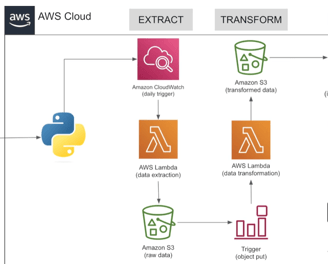
The purpose of this project is to build an ETL pipeline by using the Spotify API on AWS. it will extract the data from Spotify API, transform it to a desired format, and load it it into an AWS data store.
🧱 Project Flow:
Extract – Playlist data pulled from the Spotify API using Python + Spotipy
Trigger – Scheduled extraction via Amazon CloudWatch into Lambda
Load (Raw) – Raw data stored in Amazon S3
Transform – Lambda function processes raw data and saves it to a new folder (processed zone)
Schema Inference – AWS Glue Crawler detects new data structure
Catalog – Registered in the AWS Glue Data Catalog
Query – Data made queryable via Amazon Athena using standard SQL